

SPSS 變項轉換/資料轉換: Recode 重新編碼
Variables and Data Transformation of SPSS 1
神掌打通任督二脈‧易筋經以簡馭繁
符號意義: 統雄快訣
統雄快訣
 延伸閱讀
延伸閱讀
 進階議題
進階議題
 警示訊息
警示訊息
|
資料分析的程序應包括:1.對象(樣本代表性)分析。2.測量工具(量表信度/效度)分析。3.理論建構檢定與分析:又包括:(1)整體分析(單變項分析)(2)交叉分析(雙變項分析)(3)進階理論模型建構(多變項分析)。SPSS的檔案、介面、與資料操作。SPSS的副檔名包括:sav:資料檔,sps:程式檔,spo:輸出檔。資料檔的介面有:變項檢視介面,資料檢視介面。下載SPSS範例,進行實作。 |
SPSS Transform 資料轉換與應用時機
SPSS Transform 轉換,包括變項轉換與資料轉換,最常用的有SPSS Recode 重新編碼,與SPSS Compute 建構新變項等,其應用時機與轉換方法介述如下。
下載SPSS高等統計範例資料(右鍵下載)Analy-SPSS-Teaching.exe
下載SPSS多變項分析範例資料(右鍵下載)Analy-SPSS-Teaching-Multi.rar
下載SPSS統計與多變項習題資料(右鍵下載)Analy-SPSS-Multi_Ex.7z
下載SPSS範例資料(教材專區)Analy-SPSS-Teaching.exe
下載範例資料(教材專區):Analy-SPSS-Teaching-Multi.exe
SPSS Recode 資料重新編碼
SPSS Recode 重新編碼,可將原有變項的資料重編;或重編資料後,再建構為新變項。
Recode 重新編碼目的與時機
SPSS Recode 重新編碼,通常為將連續資料重編為類別資料;所建構的新變項,通常為將連續變項重編為類別變項,而可包括Dummy Variable 虛擬變項。
Recode 重新編碼目的與時機包括:
 理論建構分類
理論建構分類
如將「年齡」畫分為「光復前、光復」後,或「解嚴前、解嚴後」等。
參數分類
譬如將「上網時間」以「平均數 ± 1 標準誤」為「正常使用程度區間」而重分類為:「低使用程度、正常使用程度、高使用程度」等。
陡階分類
其他原始資料,發生陡階現象的情形。
Dummy Variable 虛擬變項
Dummy Variable 虛擬變項,是指將類別變項的「二元變項」、或「人為二元變項」的2個水準,轉化為「0,1」,從而可以虛擬為連續變項,也可以使用適用於連續資料的統計工具。
「二元變項」如「性別」:0 為女,1為男。
「人為二元變項」:在多元類別資料時,如果將各水準設定:沒有﹦0,有﹦1,就是將各水準建構為「人為二元變項」。
如收視率研究中:建構「臺視」變項,0 為不看臺視,1為看臺視。
有或沒有,不一定要設為「0,1」,但通常設為差距為1。
如使用網路:沒有﹦1,有﹦2。
Dummy Value 資料虛擬值
Dummy Value 虛擬值可以指以上Dummy Variable 虛擬變項中,特定的「0,1」值;也可以指任何類別變項中,對各水準設定1個數值。
Continuous Dummy Value 連續型虛擬值‧數線原則
類別資料的各水準如果具備連續性,稱為 Continuous Dummy Value 連續型虛擬值。而設定值時,為了閱讀資料的方便與一致性,建議遵守「數線原則」,亦即:左負、右正;左小、右大。
譬如:
如使用網路:沒有﹦1,有﹦2。
教育程度:小學﹦1,中學﹦2,大學﹦3,研究所﹦4 。
Dummy Value 0 虛擬值的 0 設定
在 SPSS 中,數值或字串的 null, "",space,0,各有不同的意義。
但當 SPSS 和其他軟體作檔案轉換時,以上有可能發生混淆。
在某些特殊狀況時,如以上各值沒有個別設定,有可能被視為「系統 Missing 值」。
同時,資料庫可能會使用不同的作業系統,或轉檔成不同資料格式,在某些特殊情形,會發生 0 與 "" 不分的情形。如果 0 為有效值,而 "" 卻是預設系統迷失值,會造成資料錯誤。
所以,兩害相權取其輕,當類別資料設定虛擬值時,通常-而不是一定-避免設定0。
SPSS Recode 資料重新編碼範例實作
根據資料收集的策略,某一變項可為連續資料或類別資料時,應以連續資料型態收集,優先於類別資料型態。典型的範例是「年齡」變項,應以「出生年」之連續資料型態收集,如有必要,再作事後歸類。
以下示範將「年齡」變項重編為「年齡層」變項。
〉轉換
〉重新編碼成不同變數
原始「出生年」變項為q42。
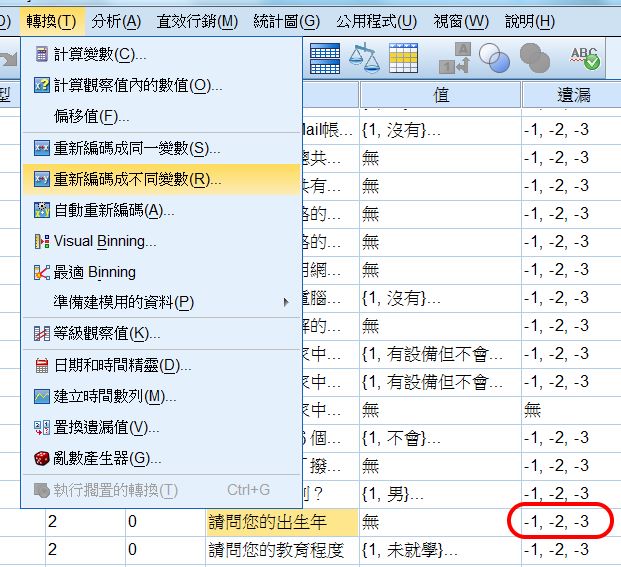
〉數值變數 → 輸出變數
「數值變數」的中譯不達意,係指原始變項。
此處為在左欄中,選 q42,即出生年。
〉按 →
q42 會移至「數值變數 → 輸出變數」中。
同時 → 會變成 ←,如果再按,就是把 q42 移除。
〉名稱
新變項名稱,宜用英文。
〉標記
即變項虛擬名、或內容敘述,可用中文。
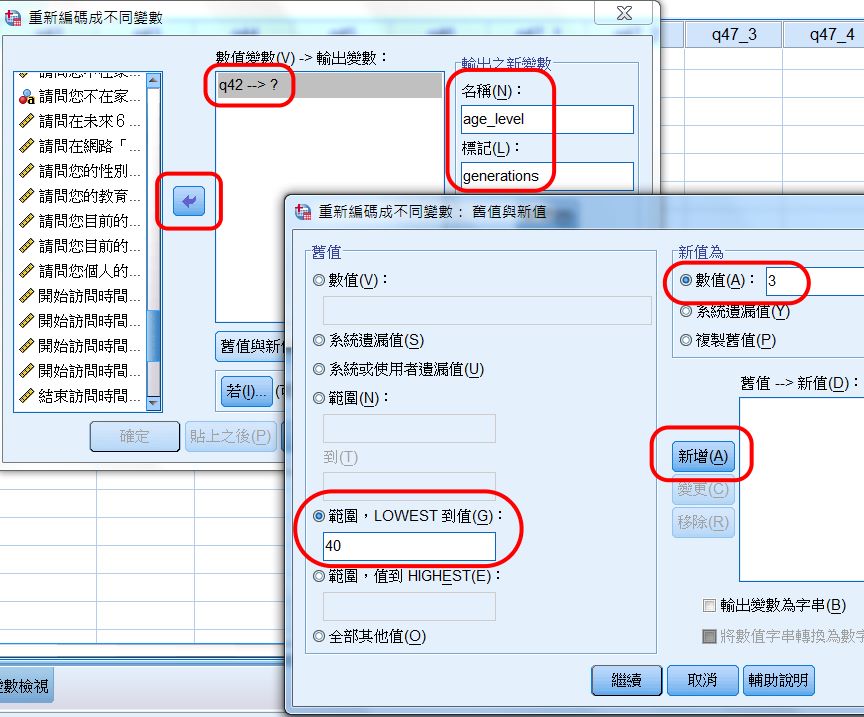
〉舊值與新值
出現「舊值與新值」對話框。
預訂設3個年齡層。採用層內樣本數平均法。
設定從民國最小年度,到民國53年。
設定這個年齡層為3,亦即高齡層。
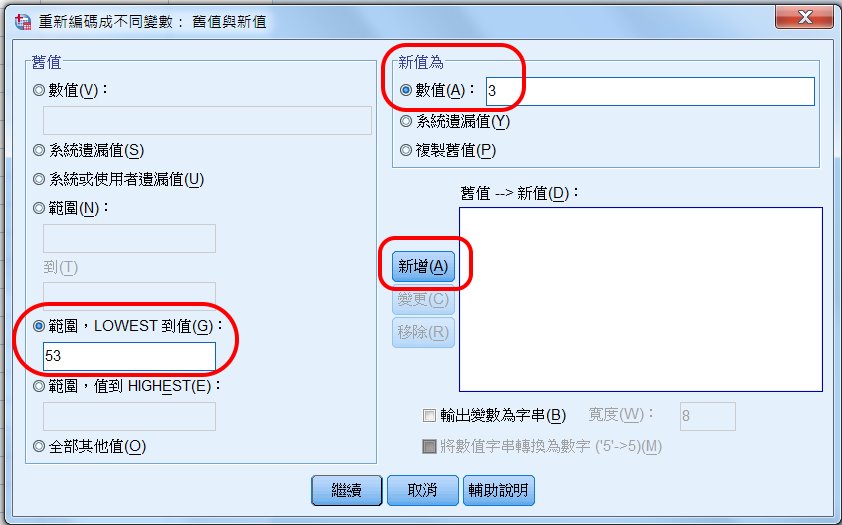
〉新增
以上設定出現在「舊值 → 新值」框中。
設定從民國54年,到民國68年。
設定這個年齡層為2,亦即中齡層。
〉新增
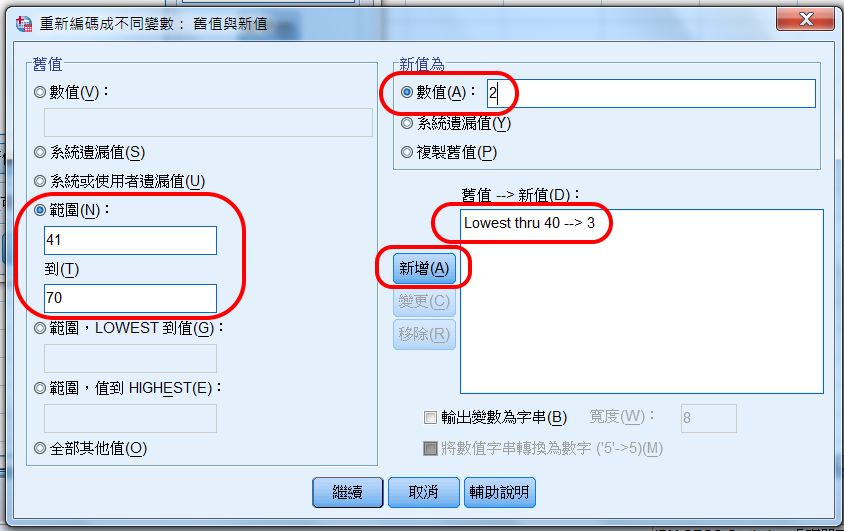
設定從民國民國69年,到民國最大年度。
設定這個年齡層為1,亦即低齡層。
3個設定都出現在「舊值 → 新值」框中。
〉系統或使用者遺漏值
選擇複製舊值,以維持 missing value 設定。
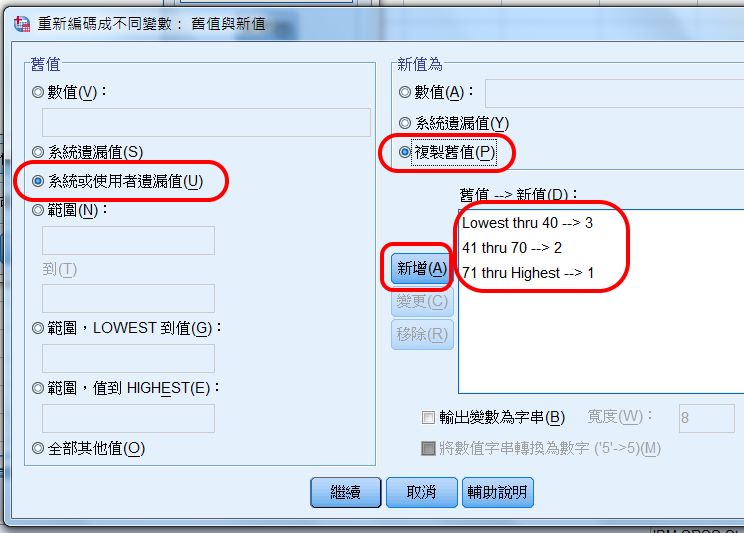
完成設定如下。
〉繼續
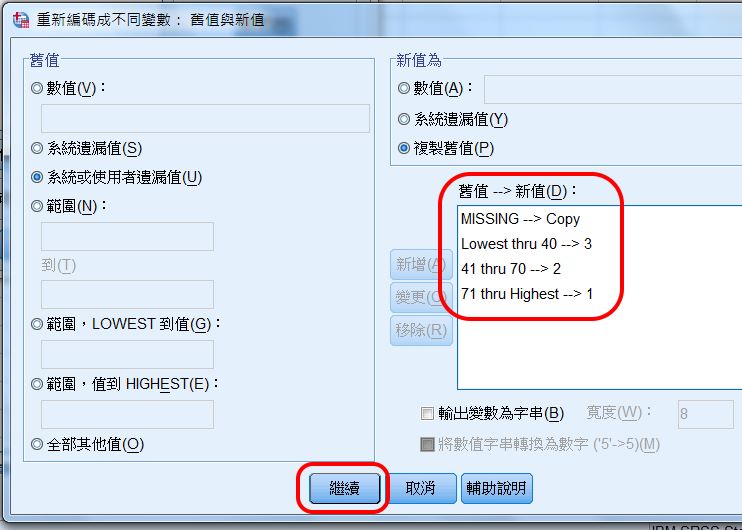
回到「重新編碼成不同變數」主對話框
〉貼上之後
按貼上之後,會將程式寫到程式檔。
使用 .sps: SPSS 程式檔
左欄是使用命令排列。
中欄是程式列序數。
右欄是詳細程式內容。
〉執行
經常會選定命令後,使用:
〉到結束。
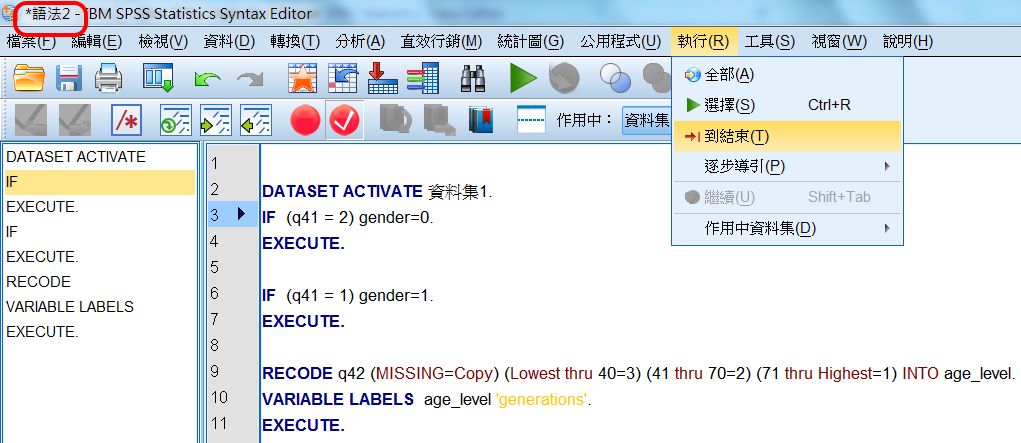
新變項檢查:修訂變項檢視介面
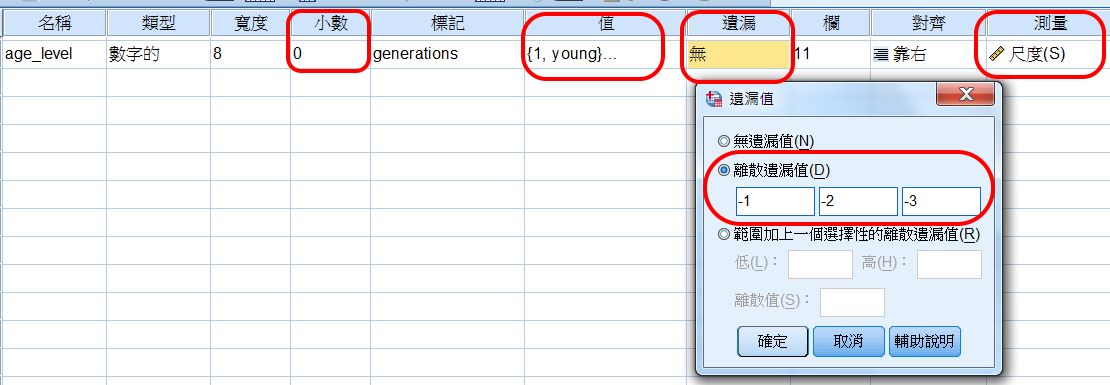
所有新轉換變項,都必須檢查相關設定。
〉類型
選「數字的」,即可作為類別、或連續資料兩用。
〉小數
這是 Dummy Value ,所以不用小數。
〉標記
避免誤漏,以利報表閱讀。
〉值
設定年齡層1,為低齡層…等。
〉遺漏:missing value 迷失值/遺漏值設定
設定 missing values。
注意:本變項的 missing value 採用負值,避免和真實值混淆。
-1:拒答
-2:沒意見(都可以)
-3:不知道(不瞭解問題)
〉測量
選「尺度」,即可作為類別、或連續資料兩用。
SPSS 的線上說明
樣本代表性檢定
數理意義的樣本代表性檢定,與資料分析中的顯著性檢定,為一體兩面。
量表信度檢定
如果是採用量表測量變項,則在理論檢定與變項分析之前,必須先作量表的信度檢定。
信度檢定是相關分析的發展與應用,所以在本系列安排在相關分析之後,和論文寫作的結構順序並不相同。
單變項分析/描述-估計
單變項分析又名獨變項分析:是論文中「研究發現(或資料分析)」章、「整體分析」節報告的方法,若是僅報告樣本統計值,便採用「描述」方法;若要推論母群,則應用「估計」的方法,又因資料型態為「類別型」或「連續型」而不同。
交叉分析/雙變項分析
分析兩個變項間的關係,常為各一應變項、自變項,與兩者關係。雙變項可能只具備關聯關係,而不具備因果關係,亦即無法辨別何者為自變項、何者為應變項。常用、也最實用的統計工具包括:卡方分析、變異數分析、與相關分析。
 統雄數學樂學/統計神掌易經筋-問卷
統雄數學樂學/統計神掌易經筋-問卷









