

驗證式因素分析 (CFA):詮釋
Factorial Validity and Confirmatory Factor Analysis
神掌打通任督二脈‧易筋經以簡馭繁
因素分析簡介
因素分析是多變項萃取與分類統計工具,又分為2類:第一類稱為探索式因素分析exploratory factor analysis, EFA),目的在萃取構念(construct)-或稱隱性因素(latent factor),並用以建構量表。建構的程序為:
1.設計題庫:依據研究目的,收集相關項目。
2.因素萃取:一般使用SPSS。
3.因素命名:根據理論邏輯進行因素命名-亦可視為「構念」命名。
4.建構量表:淨化量表項目以建構具備信度的測量工具-最常見的是「總加量表」。
第二類為驗證式(confirmatory factor analysis, CFA),是檢驗「因素效度」-或稱「因素組合」-確認構念存在、以及應用構念發展理論的方法。
因素分析是相關分析與變異數分析的綜合進階應用。
因素效度(Factorial Validity)
因素是否可以被測量到?牽涉到效度問題,而針對因素分析,又有因素效度之說,學者又有2種主張。
第一種,指在探索式因素分析(EFA)中,在各變項中可粹取出抽象 的構念因素,而因素變異量占總變異量的程度就是因素效度(Factorial Validity, Garson [171])。但這種關係和效度的原始定義並不完全一致,Nunnally [258]便建議這種概念宜正名為「因素組合」(factorial composition)比較妥當。
第二種,是以下驗證式(CFA)因素分析的延伸應用。
驗證式因素分析(CFA)
EFA分析是事前不知因素為何,經由題庫中的項目萃取而得。
CFA係依據理論建構事前已假設因素之存在與其所包含的項目,而後驗證其符合的程度。
分析因素與變項間的相關,就是驗證輻合效度(convergent validity),而分析各因素之間的的相關,就是驗證區別效度(discriminant
validity),所以CFA也是構念效度的分析工具之一。
另外,CFA也經常配合因徑分析(Path Analysis)/結構方程模型(Structural Equation Modeling, SEM),並使用其統計軟體進行分析。這些軟體的優點,是能夠自動繪製驗證之多變項概念模型。
在Amos問世之前,SPSS也可使用FA逆向分析CFA。當然Amos有許多優點,但使用SPSS,更能理解其驗證邏輯、掌握其分析意義,避免垃圾進出(GIGO)的狀況,是一個初學者練內功的好方法。
(1)分析檢定程序
a.決定研究問題
採用Jeremy J. Albright and Hun Myoung Park所介紹的美國政治態度研究為範例,研究問題為「左派與右派政治態度的差異」。
b.決定研究構念
根據研究文獻,研究者假設左派與右派政治態度的差異,可以劃分為二個主要的層次:對「社經」的態度、及對「道德」的態度。每一種態度即為一項研究「構念」,每個構念由1個總加量表測量,2量表各包含3個測項目。
c.選擇統計軟體
假設使用SPSS的 Amos。
也可以使用SPSS,更能理解其驗證邏輯、掌握其分析意義,避免垃圾進出(GIGO)的狀況,是一個初學者練內功的好方法,詳細程序如「驗證式因素分析 (CFA):應用與實作」。
d.拉出CFA因徑圖
Amos 的優點,是使用箭頭線條工具,拉出各物件(因素、項目、誤差),就可以自動跑出各種數據。
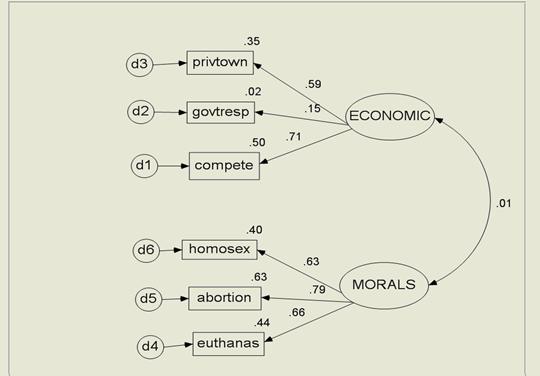
(2)檢定的標準與詮釋
橢圓形的是先驗假設的構念:社經、道德
矩形是項目
圓形是誤差
線條上的數字是相關係數
矩形右上方是判定係數,即可解釋變異量百分比。
a.輻合效度(convergent validity)
輻合效度(convergent validity)即構念與項目的「1組」相關係數,其檢定的標準與詮釋如下。
.9 < r |
效度高 |
.7< r <.9 |
效度中上 |
.3 < r <.7 |
效度中下 |
r < .3 |
效度低 |
本例除了 ECONOMIC 與 govtresp 相關偏低外,其餘均在 .35以上。
故可支持輻合效度(convergent validity)約達到可接受之中低水準。
b.區別效度(discriminant validity)
即各因素之間的的相關係數,要愈趨近於0愈好。
本例是0.01,可以通過檢定。
如果因素在3個以上,也是以「1組」相關係數作全盤評估。
c.以「共變項分析」萃取法之卡方分析
CFA若以「共變項分析」萃取法為主,則可以進一步檢驗,比較「觀察變項之共變項矩陣」與「理論模式中的共變項矩陣」的卡方分析。卡方分析有2型,最常見的是比較觀察值和期望值是否有顯著差異;而第二型「適合度分析
(Fit of Goodness)」剛好反過來,分析觀察值是否符合「理論值」(這時可能不是純隨機的期望值)的分配。所以,「適合」的指標是:
(a)卡方值必須接近於0。
(b)同時,檢定不得到達差異顯著水準。(因未達顯著水準經常是樣本不足造成的,所以「同時」的觀念非常重要。)
另外,也有一些學者提供了其他的檢定指標。
不過,「共變項分析」屬於多變項分析範圍,在此階段,我們暫不討論。
從知識論與方法論的觀察
以上 Jeremy J. Albright and Hun Myoung Park 所介紹的美國政治態度研究,在測量方法上,劃分為對「社經」的態度、及對「道德」的態度。每一種態度即為一項研究「構念」,每個構念由1個總加量表測量,2量表各包含3個測項目。
這項研究顯然沒有考量「總加量表的合理項目數」,吳統雄對心理態度行為測量、與總加量表的研究,已經指出:「總加量表的合理項目數」不得少於5,若少於5是極可能沒有意義的。
其實不待吳統雄的解說,只要知道「總加量表」,就是我們習以為常的「考卷」,「量表項目數」就是「考題數」,身經百考的人都知道,題目太少的考卷是沒有意義的,不論考國文、數學、英文…的考卷,若只有3題選擇題,有可能區別眾人的真正程度差別嗎?
但以上的範例,卻刊登在所謂頂級國際期刊上,更成為許多國際頂級大學教科書、教學網站上,在教授驗證式因素分析(CFA)、SPSS 的常用教材。
顯示這麼多的所謂頂級研究者、學術評審、教授…,其實和16世紀以前的頂級學術組織--紅衣大主教集團一樣,其實都在抄寫、累積羊皮聖經,互相吹捧以獲得宗教式的光環與資源,他們對聖經所述到底是否為知識,是既無能力辨識、更無興趣探索的。
這種在「知識論上空白」完全相同的例證,在本系列講義中,所在多有,足見是當前的常態,也作證「人類行為研究」在當前,還不是科學知識。
而我們的努力,就是要開創足以解釋、預測、實證人類行為的「第3類知識」。









