

探索式因素分析 (EFA):詮釋與實作
Exploratory Factor Analysis by SPSS
神掌打通任督二脈‧易筋經以簡馭繁
因素分析簡介
因素的意義、名稱、類型、與樣本數。
因素的意義與名稱
因素分析中之「因素 factor」,指存在而看不見、無法用物理方式觀察、測量出來的變項,如動機、創新…等等。
因素分析所歸納、萃取之「因素 factor」即為理論建構中之潛在變項 Latent Variable 或構念 Construct。
因素廣義上等同常識之 「向面 dimension」,不過,在統計專業定義上,「因素 factor」可專指因素分析之結果,必須為等距資料;而「向面 dimension」可專指「多元尺度法 Multidimensional Scaling」分析之結果,通常為等序資料。
Factors 與 Dimensions 在計量方法上的差異,前者的基礎為「相關」,而後者為等序上的「相似」。
物理 Dimensions
在物理上,Dimensions 特指可具體測量的變項,如長度、重量、時間…等,請勿混淆。
因素分析的類型
因素分析是多變項萃取與分類統計工具,又分為2類:第一類稱為探索式因素分析exploratory factor analysis, EFA),目的在萃取構念(construct)-或稱隱性因素(latent factor),並用以建構量表。建構的程序為:
1.設計題庫:依據研究目的,收集相關項目。
2.因素萃取:一般使用SPSS。
3.因素命名:根據理論邏輯進行因素命名-亦可視為「構念」命名。
4.建構量表:淨化量表項目以建構具備信度的測量工具-最常見的是「總加量表」。
第二類為驗證式(confirmatory factor analysis, CFA),是檢驗「因素效度」-或稱「因素組合」-確認構念存在、以及應用構念發展理論的方法。
因素分析是相關分析與變異數分析的綜合進階應用。
因素分析的樣本數
能否作EFA的前提與樣本數密切相關。樣本數當然是愈多愈好,但底限呢?文獻有3種主張:
1.樣本數絕對值:雖然有出現過底限100的記錄,一般仍以200為底限。
2.[樣本/項目]比:從主張5;1 到 20:1 的都有。
3.依據各種相關指標(如 Communality, KMO...詳後),對個案作反覆評估。(Zhao, MacCallum et al.)
從知識立場,當然是第三種途徑最完整,但此一途徑,許多目的是希望能以較少樣本,也能執行因素分析,若不周全,其實風險較高。在各方考量下,對非統計專業者,就不知如何著手作因素分析了。
統雄老師推算過研究人類行為的最低樣本數為200,所以建議準用這個樣本數為最低限。
不同刻度的問項,是否可合併作因素分析?
不同刻度的問項,譬如6刻度、7刻度、100刻度的問項,是否可合併在一個資料集內作因素分析?
如果是採用 SPSS 以及統雄老師講義介述的程序,是可以的。
因為 SPSS 會將同一資料集中的問項,全部先標準化,再進行分析。
刻度的資料標準化
但在實務上要注意,就一個完整的研究,可能在因素分析之前,先會有基本分析。
譬如為何會考量合併6刻度、7刻度、100刻度的問項?可能是這些項目原來來自3個不同的量表,但研究者認為,可能只是名稱不同;或來自3個不同的研究,但研究者認為其中的「構念」可能是相同或有關的。
在以上的情形,會先比較這3組量表的統計值,各量表的原始平均數、標準差,都會造成視覺上比較的障礙,所以,通常會先將3個量表作資料標準化。雖然標準化為任何刻度都可以,通常會全部標準化為 0~1 之間。
下載SPSS範例
 下載SPSS高等統計範例資料(右鍵下載)Analy-SPSS-Teaching.exe
下載SPSS高等統計範例資料(右鍵下載)Analy-SPSS-Teaching.exe
下載SPSS多變項分析範例資料(右鍵下載)Analy-SPSS-Teaching-Multi.rar
下載SPSS統計與多變項習題資料(右鍵下載)Analy-SPSS-Multi_Ex.7z
下載SPSS範例資料(教材專區)Analy-SPSS-Teaching.exe
下載範例資料(教材專區):Analy-SPSS-Teaching-Multi.exe
探索式因素分析(EFA): SPSS應用
探索式因素分析(EFA) 的概念模型如下:
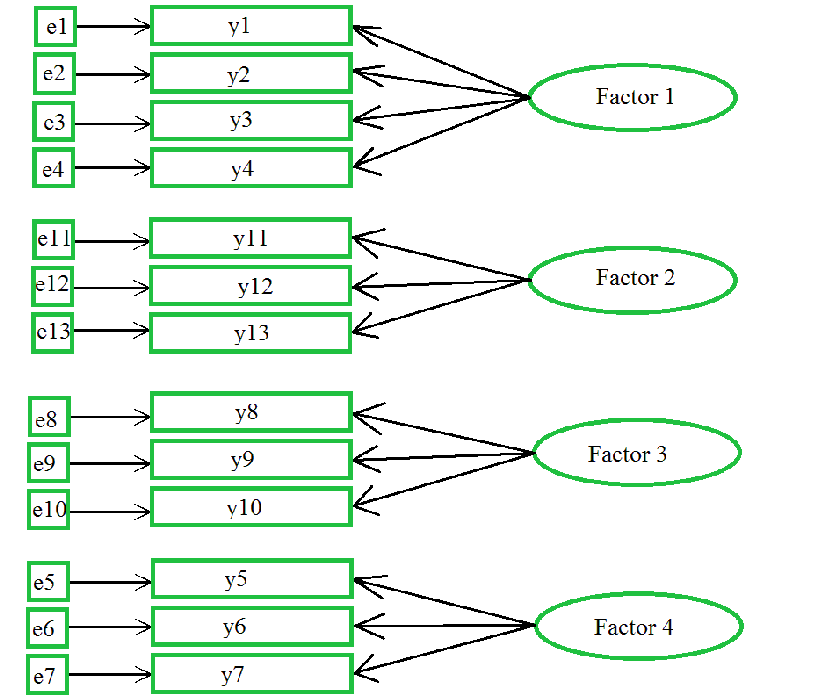
對Y1 項目的測量,是受到潛在變項 Latent Variable(F1,因素1)的影響,與誤差(e1)的結果。
F1 會影響 Y1, Y2, Y3, Y4,即存在顯著相關性;但不影響其他 Y,即,F1 與其他 Yn 兩兩相關為0。
同理類推 F2, F3, F4,且 F1, F2, F3, F4 彼此獨立而互斥,即 Fn 之間兩兩相關為0。
亦即,F 為Y 的自變項,Y1, Y2, … Y13,為可測量之項目,「 探索式因素分析(EFA)」即將逆向由 Yn 歸納、萃取出其各潛在變項 Latent Variable為何。
 因素內的項目數
因素內的項目數
因素內的項目,除非為可具體物理測量者,其數目可不受限制。譬如:身高、體重 2 項目,可能可以合成為1個因素,稱為「體型」。
但若項目為「存在而不可見」的心理、態度項目,則因素內的項目數如果小於5,是可能沒有意義的。
「 探索式因素分析(EFA)」通常是要協助建構心理、態度量表,而量表就是等同「考卷」,如果想要測量數學認知、英文認知的考卷,只有 4 題以下選擇題,是不可能有效度意義的。
以上圖例,出自國際頂級教科書,統雄老師採用其的另一目的,就是指出:當前國際統計、計量分析研究生態,還是處於宗教型、紅衣大主教抄寫羊皮聖經、缺乏科學化行為研究共識的階段。
應用範例
範例目的:網路使用沉迷行為分析
這是一個習題,不是真正的研究。
分析的程序為:
1.設計題庫:依據研究目的,收集相關項目。
2.因素萃取:一般使用SPSS。
3.因素命名:根據理論邏輯進行因素命名-亦可視為「構念」命名。
4.建構量表:淨化量表項目以建構具備信度的測量工具-最常見的是「總加量表」。
設計題庫
依據研究目的,收集相關項目。
本例 題庫:52題(即項目,或狹義的變項)
擬萃取出若干獨立而互斥的構念(因素),以解釋網路使用行為。
因素萃取
使用SPSS分析的程序如下。
〉資料縮減
〉因子
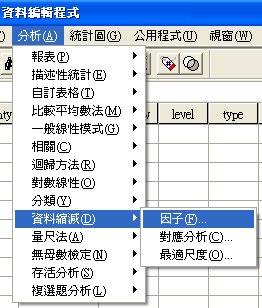
選擇要萃取的項目(變數)本例是C1~D26。
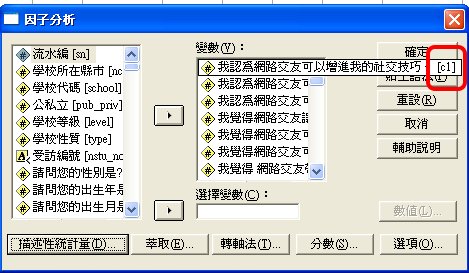
SPSS 使用shift 拉變項的時候,有可能會掉,要小心檢查。
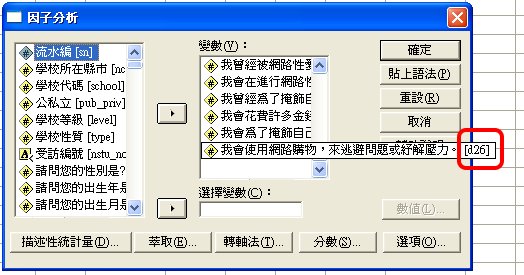
〉描述性統計量
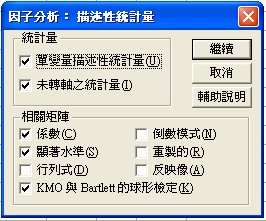
〉萃取
〉主成分分析
萃取的方法有多種,最常用的為:
主成分法(Principal Component Analysis):以變異數分析為基礎。
其次為:
狹義的主因素法(Principal Factor Analysis):以共變數分析為基礎。
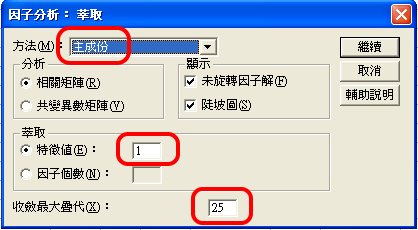
特徵值(Eigenvalue)
每因素所含各項目所貢獻的量。
每1個項目的最高特徵值是1,總特徵值數,就是項目數,所以本例就是52。通常認為1個因素的貢獻要超過1個項目才有意義,所以預設為1以上,才進行萃取。
另一個選項〈因子個數〉,預設為不選,而採用反覆萃取,至選定之特徵值為準。
若是選擇此項,是由研究者決定萃取的因素個數,通常是第二輪以後的作法,或是進行「驗證式因素分析」時,強迫建構因素使用。
收斂最大疊代(Maximum Iterations for Convergence)
又一個難以望文生義的中文統計名詞。
意指最多反覆萃取幾次,預設25為早期個人電腦規格最高能達成數。隨著電腦硬體大幅進步,已可突破。
通常保留預設,但如果無法在25次內完成,則會出現以下訊息:
「無法收斂於2個疊代。(收斂=.0X)。」
則再將「收斂最大疊代」數值改為「X」以上。
〉轉軸法
|
因素必須追求「獨立而互斥」,其在幾何上的意義,就是資料在「2個獨立而互斥因素」構成的直角平面座標上,會形成迴歸直線。有時資料會受到第3個以上因素的影響,直接視覺並無直角平面、也無直線,但旋轉後,會接近此前提之要求。 轉軸(如右圖)可以增加因素內項目的貢獻度、不同因素之間的獨立性,建議必選。
|
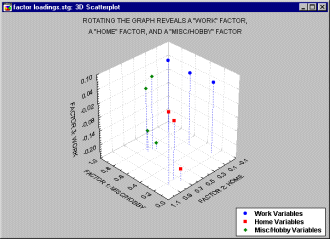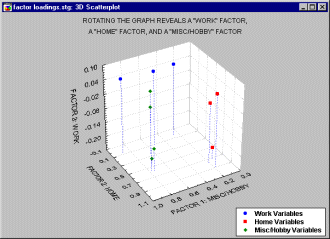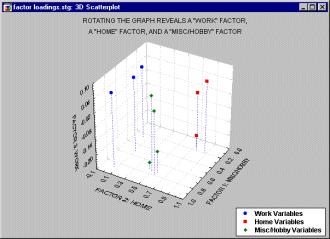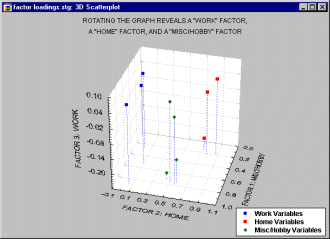 |
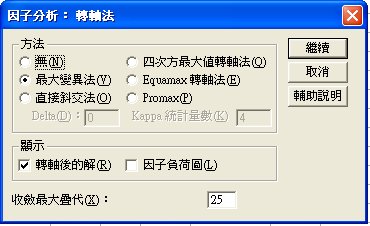
〉分數:產生新構念變項(因素)之分數
照常用的量表就是總加量表,傳統上在經過因素分析、取捨項目後,就是將淨化後的項目總加,作為建構新構念(因素)變項的分數。
現在因素分析可以提供更細緻的權重方法,譬如迴歸法就是以項目對因素的迴歸係數來權重後再總加。

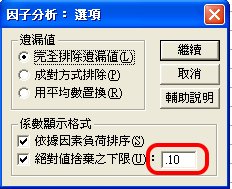
〉選項
因素負荷量
在因素分析中,Missing Value 的處理,為避免項目間不平衡產生的誤差,應該選擇 Listwise。
因素負荷量就是項目對因素的標準迴歸係數,介於0~1之間。其意義評估與相關分析同。
預設為0.1以下就不顯示了,當然,0.3以下就幾無重要性了。
系統預設報表為按照變項輸入順序排序,在後續建構量表時,閱讀較不順,所以改選按相關程度排序。
因素分析的報表
基本資料
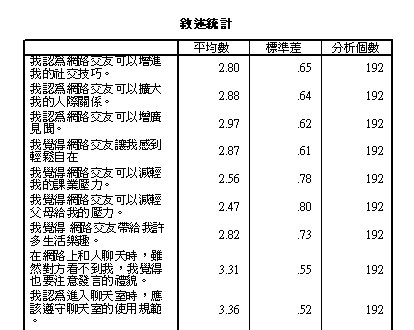
相關係數矩陣
觀察項目間的相關程度。
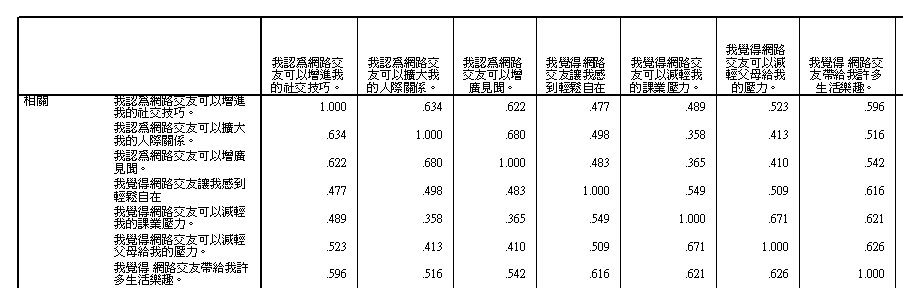
可行性檢定
因素分析繼續往下作有沒有意義?
KMO / MSA 因素獨立性考驗
因素之間必須彼此獨立互斥,所以必須作因素獨立性考驗,其實就是「相關」的「逆應用」。
SPP 提供 2 個因素獨立性分析:KMO 考驗與 Bartlett 樣本球型檢定。
KMO 考驗沒有通用中文譯名,是由該考驗分析的研究作者3人: Kaiser-Meyer-Olkin test 命名而來。
KMO 考驗又是 MSA, Measure of sampling adequacy 分析的延伸,一般直譯為:樣本正確性測驗,頗不達意,故統雄老師將其統一譯為「因素獨立性考驗」,而 MSA 是「雙因素獨立性考驗」而 KMO 是「多因素獨立性考驗」。
MSA 定義公式如下:
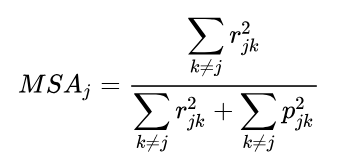
j, k:2 因素
r2:r, j 的判定係數
p2:r, j 的淨相關的判定係數
r, j 的淨相關的判定係數就是 2 因素相同的部分,所以其值要愈小,因素獨立性愈膏。
而 KMO 就是各 MSA 的總加觀念,定義公式如下:
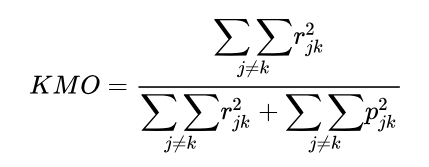
由於因素獨立性相當於信效度的觀念(百分比、面積),所以,作者建議宜大於0.6。
而0.8 以上,亦即具備高因素獨立性。
Bartlett 樣本球型檢定
類似卡方分析概念,如果各項目樣本落點平均分配(像球型),即不顯著,就是缺乏因素間的獨立互斥。所以本項檢定必須顯著才可通過。

共同性
共同性(Communality),即項目可貢獻至因素之程度。
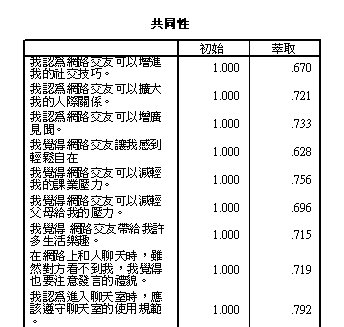
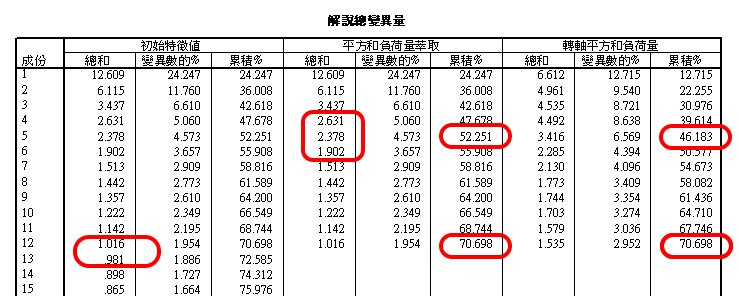
因素數目取捨
根據預設捨棄Eigenvalue<1 的因素,本例剩餘12個因素。
平方和負荷量:即判定係數。
變異數的%:反映各因素可解釋總變異量的百分比。
對人類行為而言,真正獨立互斥之因素很少多於7個,所以必須再進一步取捨。
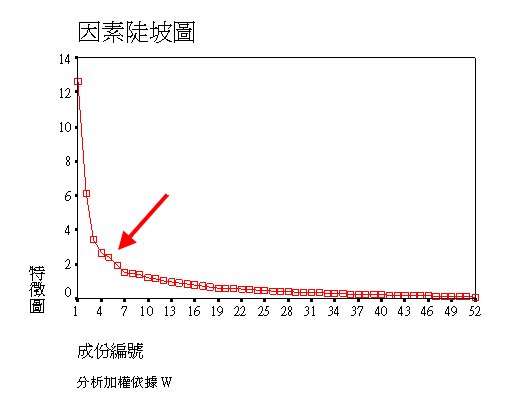
從平方和負荷量總和發現,第5因素與前後因素尚有差距,而第6因素以後,因素間差距變小,稱為發生「陡階(Scree)」現象。
陡階檢定
根據陡階圖,決定選擇前5項因素。
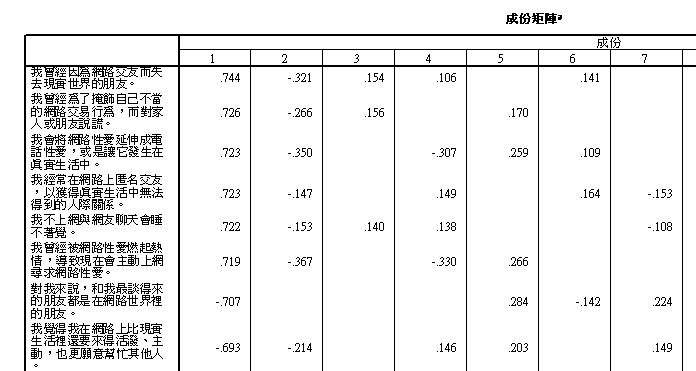
成分矩陣
成分就是因素, 這是轉軸前,各因素所含之項目分析。


因素命名
根據理論邏輯進行因素命名-亦可視為「構念」命名。
通常會以轉軸後的矩陣,也以「陡階檢驗」分派各因素所含之項目;通常取正相關項目,但如果測量設計時,就有設計「反面項目」,則負相關也納入。但也可能有特殊情況,以下將有例子。
以各因素所包含的項目為準,進行命名。
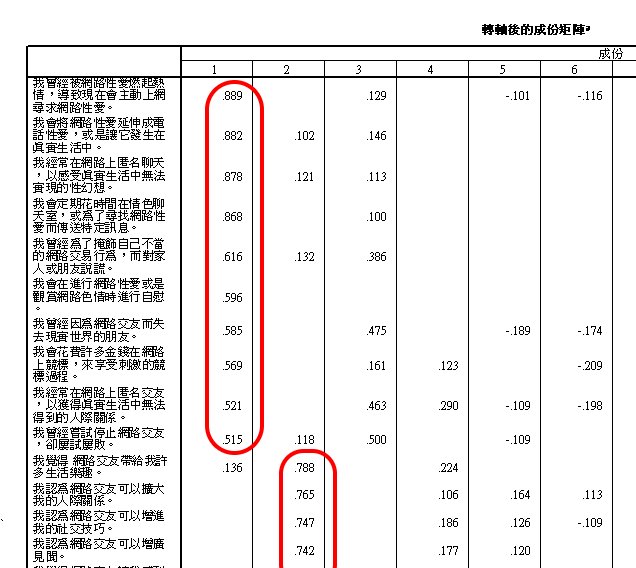
本例的第一個因素,包括的10個項目,都與情色有關,故可命名為:
情色行為
包括:d21, d20, d19, d18, d23, d22, d9, d24, d10, d12
其他4個因素,則可分別命名為:
交友行為
包括:c7, c2, c1, c3, c4, c5, c6, c14
收集資訊行為
包括:d16, d17, d11, d15, d7, d8
在本因素中,包括c17:「我常常會因為使用網路和爸媽吵架或遭到責罵」,且為負相關 -.579。其值在中小之間,唯與其他6個項目均欠缺直接邏輯關係,故不納入。
但,是否意味,「收集資訊行為」是一種社會相信中的「積極行為」,所以促成與父母關係較好?是一個可未來探索的問題。
遊戲行為
包括:d5, d1, d2, d3, d4, d6
禮儀行為
建構量表與因素分數
建構量表與其因素分數計算,分作:原始項目分數總加法,和自動構念變項權重分數法 2 種。
原始項目分數總加法
將各因素所包含的項目總加,作為其因素分數。
如「情色行為」因素包括:d21, d20, d19, d18, d23, d22, d9, d24, d10, d12
則其因素分數為其10項目之總加,由於各因素所包含的項目可能不一致,故常取其平均數,以利比較。
自動構念變項權重分數法
如果在前述階段,選擇了以下設定:
〉分數:產生新構念變項(因素)之分數
便可 在「變數檢視」可以發現自動產生新構念變項、與其權重分數。
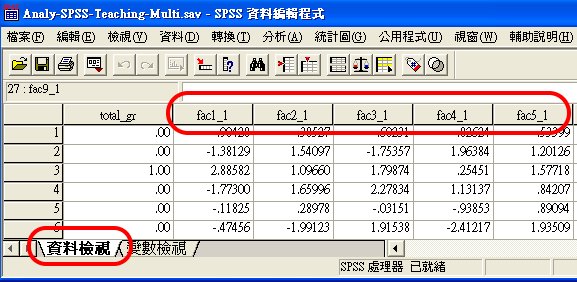
在「資料檢視」則可發現各樣本的構念變項分數。

 權重分數呢?還是原始分數?
權重分數呢?還是原始分數?
SPSS 自動產生的構念變項分數是權重分數,而一般量表在統計時,都是使用原始分數總加?
這兩者之間有優劣嗎?
這好比1份25題的考卷,原始總加量表就是每題平均4分;而權重量表,則是收回全體考卷後,再統計比較多人會答的題目,評分高一點;而較少人會答的題目,評分低一點,這就是權重分數。
權重分數的效果,可能會使觀察對象之間的差異較小;而原始分數的效果,可能會使觀察對象之間的差異較大。
所以,採用那一種分數,還是要從理論基礎、研究的特殊目的,再加斟酌。
因素效度/驗證式因素分析(CFA)
![]() 使用 Maximum Likelihood 方法的因素分析:http://www.unt.edu/rss/class/Jon/SPSS_SC/Module9/M9_FA/SPSS_M9_FA1.htm
使用 Maximum Likelihood 方法的因素分析:http://www.unt.edu/rss/class/Jon/SPSS_SC/Module9/M9_FA/SPSS_M9_FA1.htm







