

共變數分析/詮釋
Analysis of Covariance, ANCOVA, GLM
神掌打通任督二脈‧易筋經以簡馭繁
共變模型的用途
一般線性模型 General Linear Model, GLM
共變數分析的前提
共變數分析/共變模型檢定程序
|
共變數分析(ANCOVA)有3大主要用途: |
共變數分析特色
共變數(Covariance)是共變項影響的測量值,共變數分析是基於共變數定義的應用。
共變數 Covariance
是以面積分析線性關係的創新思想、抽象 觀念。
 共變數定義公式
共變數定義公式
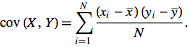
有些文獻分母為 N-1,是指小樣本時,應作不偏 (unbiased) 校正。
共變數圖形示例
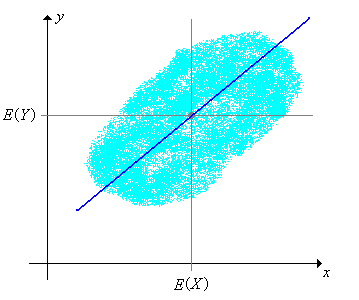
以X,Y
兩者平均數為原點,若
(X * Y)之累積和為正,則存在正相關斜線。
若
(X * Y)之累積和為負,則存在負相關斜線。
若
(X * Y)之累積和為0,則存在垂直、或水平直線。
若
(X = Y),則其累積和為直線之變異數。
由變異數導出常態分配、中央極限定理。
共變數同時可導出相關分析/簡單迴歸、與共變數分析/共變模型分析。
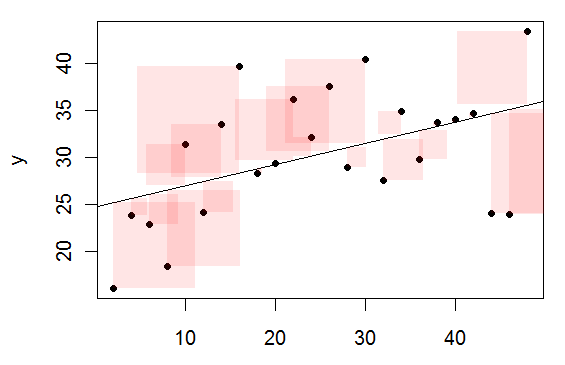
共變數與相關分析/簡單迴歸
共變數定義,正好是相關分析/簡單迴歸的「分子」。
下圖是一個示例。
故相關係數可以用共變數表示為:
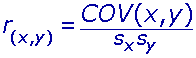
共變數與共變數分析/共變模型分析
共變數分析(Analysis of covariance, ANCOVA)/共變模型分析,是對存在「共變項」的多變項分析與模型建構。
共變項
共變項就是在類別自變項外,在觀察過程中,還存在會對應變項產生「迴歸影響」的變項。
傳統習稱的「共變數分析」,以當前理論建構與科學中文化的概念來看,宜稱為「共變項分析」或「共變模型分析」。
共變模型是結合變異數分析與迴歸分析、一般線性模型技術,排除共變項在理論建構中的影響,以觀察自變項對應變項的真正效果。
由於分析的是「迴歸影響」, 共變模型中的共變項、應變項都必須是連續資料。
Covariance is a measure of how much two variables change together and how strong the relationship is between them. Analysis of covariance (ANCOVA) is a general linear model which blends ANOVA and regression. ANCOVA evaluates whether population means of a dependent variable (DV) are equal across levels of a categorical independent variable (IV), while statistically controlling for the effects of other continuous variables that are not of primary interest, known as covariates (CV). Therefore, when performing ANCOVA, we are adjusting the DV means to what they would be if all groups were equal on the CV.
理論概念模型 |
分析方法與其說明 |
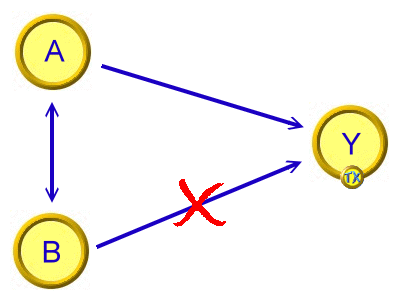
共變模型又稱共變數分析或共變項分析因子間關係:彼此不獨立,且相互平行
|
目的本分析旨在排除與主要自變項存在共線性(collinearity)的「共變項」-即另1自變項,以淨化主要自變項的效果。 共線性係指變項間存在相關關係,亦即在幾何上的平行關係。 B與Y、或B與A有共變關係-即具備共線性。B必須是連續資料。以A預測Y時,其中可能包含B的貢獻。 排除B的貢獻,分析A真正的預測力。 共線性與交互作用是互斥的,所以共變數分析與以上交互作用分析是不能同時存在的。 要作共變數分析之前,必須先排除有交互作用關係。 SPSS 工具自變項為類別資料:一般線性模式(GLM)之ANCOVA。 自變項為連續資料:多元迴歸分析。 |
共變模型的用途
共變數分析(ANCOVA)有3大主要用途:
1.淨化類別自變項。進行雙變項分析,某些類別自變項可能受到共變項影響,產生假性差異,則應排除共變項,淨化獨立自變項的效果,考驗淨化後,是否仍有顯著差異。
譬如,網路消費研究, 我們發現:女性網路消費力遠超過男性。但進一步思考,會不會存在「開始上網時間」的共變項?亦即消費力其實是與網路使用經驗的長短有關。 為了消除疑慮,決定排除這個共變項,確認性別這個自變項的效果。
(註:當自變項均為連續資料時,使用多元迴歸分析淨化自變項。分析後,未達顯著水準的自變項,就是應排除的共變項。)
2.作為實驗推論的「統計控制」。當自變項均為類別資料時,尤其是在採用實驗法(尤其是準實驗法)時,實驗的結果如果要能推論全體,通常必須進行以下2項控制之一:第一、實驗控制:即樣本的來源必須符合隨機性。第二、統計控制:排除其他非實驗所觀察的變項,亦即在實驗處理前後,採用2次以上測量並配合共變數分析以排除誤差。在實施「前測-後測」時,將前測當作共變項排除,避免產生假性差異-亦即:組間存在先天差異,不是操作自變項之實驗處理造成的。
譬如,導入資訊教學法研究,設計2班各以資訊法、傳統法教學,在學期結束後,測量其學習成就。但學習成就之差異,不僅是教學法,而有智商的影響,所以應在學期開始前,測量其智商作為共變項。
3.發現與探索其他「調節模型」。以上的程序是假設、檢定並排除與應變項形成迴歸線的共變項-即除類別自變項之外的「連續自變項」。而排除的前提,是類別自變項的每一個水準,其迴歸線為平行的、即迴歸係數是相同的。但有時,類別自變項的每一個水準中,其共變項與應變項的迴歸線不為平行,而反映可能存在「調節模型」。由於「調節模型」的自變項為類別資料,而共變項為連續資料,再進一步檢定模型前,會將共變項歸類為類別資料。這項用途,相當於「分析辯難」的一個例子。
ANCOVA can be used to increase statistical power (the ability to find a
significant difference between groups when one exists) by reducing the
within-group error variance.
Another use of ANCOVA is to adjust for preexisting differences in nonequivalent
(intact) groups. This controversial application aims at correcting for initial
group differences (prior to group assignment) that exists on DV among several
intact groups. In this situation, participants cannot be made equal through
random assignment, so CVs are used to adjust scores and make participants more
similar than without the CV. However, even with the use of covariates, there are
no statistical techniques that can equate unequal groups. Furthermore, the CV
may be so intimately related to the IV that removing the variance on the DV
associated with the CV would remove considerable variance on the DV, rendering
the results meaningless.
一般線性模型 General Linear Model, GLM
共變數分析屬於「一般線性模型/多變項線性迴歸( general linear model, GLM)/ multivariate linear regression」的應用。
共變數分析的前提
Assumption 1: Randomness and Independent Sampling
樣本符合隨機性、獨立性。
Observations must be randomly sampled from the population and independent from each other. If this assumption is violated, the test will produce inaccurate results.
Assumption 2: Normality
變項符合常態分配。
There must be a normal distribution of the DV in the population. In the event that a distribution that is nonnormal (e.g., skewed or kurtotic) and sample sizes are small, p-values may be invalid.
Assumption 3: Homogeneity of Variances
變異數具備同質性。
The variances of the DV must be equal for all levels of the IV and the CV.
Assumption 4: Homogeneity of Regression Slopes
共變項與自變項的斜率具備同質性,亦即共線性。
The slope of the line predicting the DV from the CV must be equal for each level
of the IV. That is, the CV must not have differential effects on the DV at
different levels of the IV. This assumption is violated when there is a
significant interaction between the IV and the CV.
If this assumption is violated, ANCOVA should not be performed. If the
correlations of the covariates with the DV are very different in different cells
of the design, gross misinterpretations of results may occur. In ANCOVA, we
basically perform a regression analysis within each cell to partition out the
variance component due to the CV. The homogeneity of slopes assumption implies
that we perform this regression analysis subject to the constraint that all
regression equations (slopes) across the cells of the design are the same. If
this is not the case, serious biases may occur.
共變數分析/共變模型檢定程序
共變數分析/共變模型檢定程序分為3個步驟:
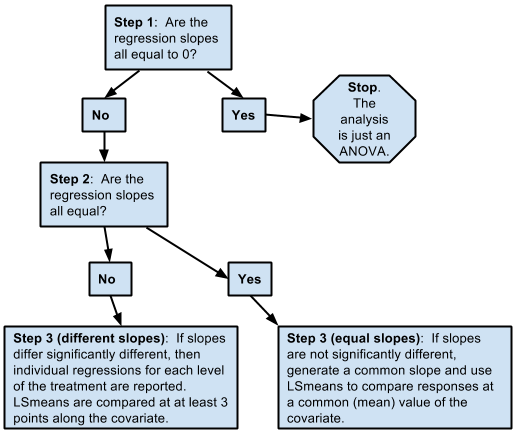
共變數分析/共變模型檢定程序第一步
共變項是否存在?亦即共變項與應變項之迴歸線,是否為0?
共變項與應變項之迴歸線如果為0
不存在共變項,即作變異數分析即可。
共變項與應變項之迴歸線如果不為0
必須繼續作共變數分析/共變模型檢定。
共變數分析/共變模型檢定程序第二步
類別自變項之各水準,其組內的「共變項與應變項之迴歸線」是否平行?
在實驗法中,類別自變項就是不同實驗處理的組別。
就 SPSS 應用而言,以上2步驟,是一次完成。
共變數分析/共變模型檢定程序第三步
根據組內的「共變項與應變項之迴歸線」是否平行,不同處理如下:
「共變項與應變項之迴歸線」平行
繼續作共變數分析,排除共變項,檢定類別自變項是否顯著。
「共變項與應變項之迴歸線」不平行
反映可能另外存在「調節模型」。由於「調節模型」的自變項為類別資料,而共變項為連續資料,再進一步檢定模型前,會將共變項歸類為類別資料。









