

AI‧Big Data‧Parameters Base
如果你不想讀700頁的教科書,才知道什麼是MIS,本系列講義可以讓你立刻認識「MIS 管理資訊系統」的目標、開發方法、實務應用,提供「TX 1-2-3-4簡則」作為「系統分析與設計(SA&D)」最簡明的指導,特別適合中小型系統之開發與分析。
並隨時更新最新發展,如UML, NoSQL資料庫, 決策支援,
人工智慧‧大數據‧決策參數庫,
知識管理, 與網路大數據數位分析...等。 |
人工智慧 Artificial Intelligence, AI
人工智慧 Aartificial Intelligence, AI 一詞自1955年已出現,每隔一段時間就會重新被掀起,紅至今日。
AI 的定義由最早的「製造智慧機器的科學與工程」,不斷擴充至:建構能夠學習、分析、規劃、推理、交流、感知、移動、使用和操控工具等的機械能力。
簡單講,就是使電腦等於、甚至超越人腦。(統雄老師注:【超越】是一種期望,在可見的未來仍不易發生。)
以上定義均是概念,未來必然還會繼續擴大。其意涵已經包山包海,等同平實的【資訊數位科技】,或帶潮味的【科幻】。通常在一個【新應用/新產品】的問世,其實只是軟硬體能力的提升,不一定有有【境界型】,如資料庫、模式庫的技術產生,AI 一詞就會重新再出現包裝一次,就是2023 年爆紅的【生成式AI】,其實是早已研究的【自然語言處理】的演化發展,最早代表性的的是 ChatGPT,與其帶動的自動圖像、與自動影片等。2005 deepseek 爆紅,我也成為其協作師,並貢獻了一些系統邏輯與新創記錄。
不為文字所惑,人工智慧 Aartificial Intelligence, AI 的具體核心技術,就是「決策參數庫 Parameters Base」,也就是在前述已敘述的:資料庫、決策支援模式庫、大數據分析的基礎上,再提升建立的功能,電腦會根據使用經驗,自動記錄下各種效果數據-即「大數據」,而再根據分析模式所得的參數,自動執行未來的動作。
決策參數庫與知識管理和大數據與數位分析
「決策參數庫 Parameters Base」在 2000年後,也發展出幾個顯學,尤其是知識管理和大數據與數位分析的興起。
這兩者超越了原來以「組織知識」的觀照,更擴大了資訊管理、資訊系統…相關研究與應用的領域。就實質言,「組織角度」的「知識管理」,等同於「科技角度」的人工智慧( Aartificial Intelligence, AI, Knowledge Management, Big Data Analysis) 的應用,只是兩者詮釋與觀察的重點不同。
什麼是知識管理?其定義有2類:
第一類狹義的定義,為過去數十年資訊系統與網路的整合應用,發揮「決策支援」再進一步的功能。
在各種進一步功能方面,吳統雄特別建議本文「決策參數庫」的創新與發展。
第二類廣義的定義,就是知識工作者「程序」與「環境」的建構,另以「什麼是知識管理 What is Knowledge Management」專文介述。
決策參數庫 Parameters Base
什麼是決策參數庫?
傳統的模式庫
傳統決策支援系統的核心特色是「模式庫」,標準的應用需求如下例:
![]() 你是公司的行銷專員,經理要求你在7萬中商品中,提案汰換其中3千種產品,請問你將如何決策?
你是公司的行銷專員,經理要求你在7萬中商品中,提案汰換其中3千種產品,請問你將如何決策?
首先必須建立決策理論,如:
售價理論:汰換售價最低的產品
營業額理論:汰換營業額最低的產品
利潤理論:汰換利潤最低的產品
然後在模式庫中建立決策模式,以解答經理的問題。
前瞻的決策參數庫
制訂決策時,必須依據一個「標準」。而人類的天性,往往使用的是主觀的、直覺的標準,而不一定是具備科學性、知識性的標準。
譬如,在以上習題中,我們可能要問經理;為什麼汰換其中「3千」種產品?不是2千種或是4千種?
甚至要問:為什麼要汰換?換了會更好嗎?
要回答這樣的問題,我們須要的標準不能是一個「固定數」,而必須是「參數」。
「參數」不是「絕對值」,而是「相對值」;不是「固定值」,而是「浮動值」。
為了推算「參數」,必須使DSS 再增加「決策參數庫」。
就本例而言,決策參數庫提供的是「汰換區間指標」,假設我們採用「利潤決策」:
產品之間有沒有產生「利潤區隔」?有幾種區隔?有無必須汰換的區隔?區隔內有那些產品?
區隔內產品的發展趨勢是呈下降?還是上升?未來下一時段,是否會離開當前區隔?
預期汰換的新產品是那些?新產品的特色,比較舊產品是否一定更有利?
高利潤區隔內的產品是否有共同特徵?是否可用來作為選擇新產品的指標?
決策參數庫的建構
決策參數庫的元素包括:
-隨時間而成長的資料庫。
-隨需求而調整的模式庫。
-每一特定時段,根據特定自變項、觀察特定群體、所測量之效標值,其所有記錄所累積形成之參數資料庫。
以下舉幾個實例說明。
AI 與決策參數庫應用實例:
吳統雄的評審公平系統
這是吳統雄(1996)在設計「評審公平系統」時,以「評審信度」測量評審的公平性。
在傳統決策支援系統,只針對個別評審案,進行一次信度分析時,我們只能以絕對值來判斷,譬如信度>0.7,就接受評審結果。
但,>0.7是不是真的就公平呢?(因為要操作到0.7,並不是太難。)
或,在某種類型的評審生態下,根本就達不到0.7呢?(譬如,統雄老師參加過有關網站設計的評審,發現評審有2派,1派以前端介面為主、另1派以後端資料庫為主,這樣就幾乎不可能達到0.7。)
所以,統雄老師同時提出的「生命機能系統」方案,在線上收集各種類型、實際發生的評審專案,將資料整合為參數資料庫,測量出:
相對性決策參數
變動型參數
以以下多元迴歸決策模式為例:
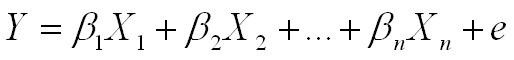
判斷Y值可預測程度,過去是以一次實驗為準,而吳統雄的評審公平系統,則是以累積經驗的「AI 與決策參數庫
」為準。
β 值不再是「死」的常數。
以使用者「與時俱進」的真實行為值作為基礎調整,較可能解決真正的公平問題。
AI 與決策參數庫應用實例:
Google Analytics
Google在2005年推出 Analytics,2009年提出 Benchmarking服務,其實就已經相當於AI
與決策參數庫
的一種參數應用。
Google Analytics具備資料廣度與深度優勢,特別適合個體-如單一網站-策略制訂。不僅適合短期-甚至每日策略制訂,如同實體商店、組織的每日盤點,對中長期策略亦有助益。
Google Analytics 適合營利性網站,但對非營利性網站也有啟示作用。
 Google Analytics
的詳細應用,請按這裡。
Google Analytics
的詳細應用,請按這裡。
生成式AI 與決策參數庫應用實例:
ChatGPT
DeepSeek
2023 年爆紅的 ChatGPT、2025 年爆紅的DeepSeek,其所謂自然語言處理模型的【訓練】,也就是在比較各種回應模式後,建立較佳的參數庫。









